The purpose of Replicate Seed Data Concurrent Program is to populate the Installed modules seeded values, so that new organizations can use the seeded data.
Whenever new Organizations are created (under the Multi-org Setup), running Replicate Seed data is a pre-requisite step before you can start working in the newly created organization.
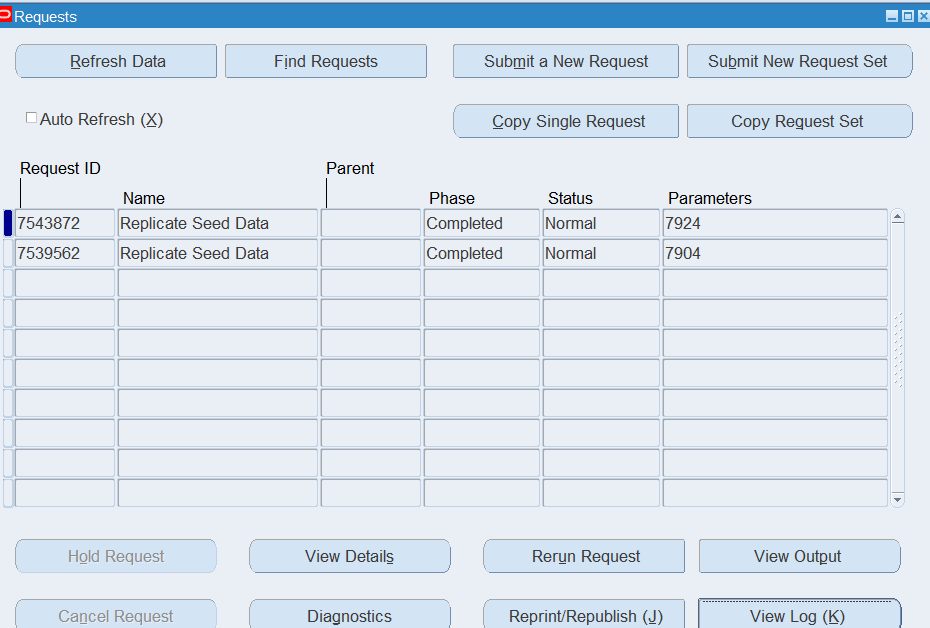
The Replicate Seed Data Concurrent Program can be run for a particular Operating Unit or for all Operating Units (as it is not mandatory parameter) but you cannot run the program for a particular module.
How to Run the Replicate Seed Data ?
Responsibility : System Administrator
Navigation : Request –> Run
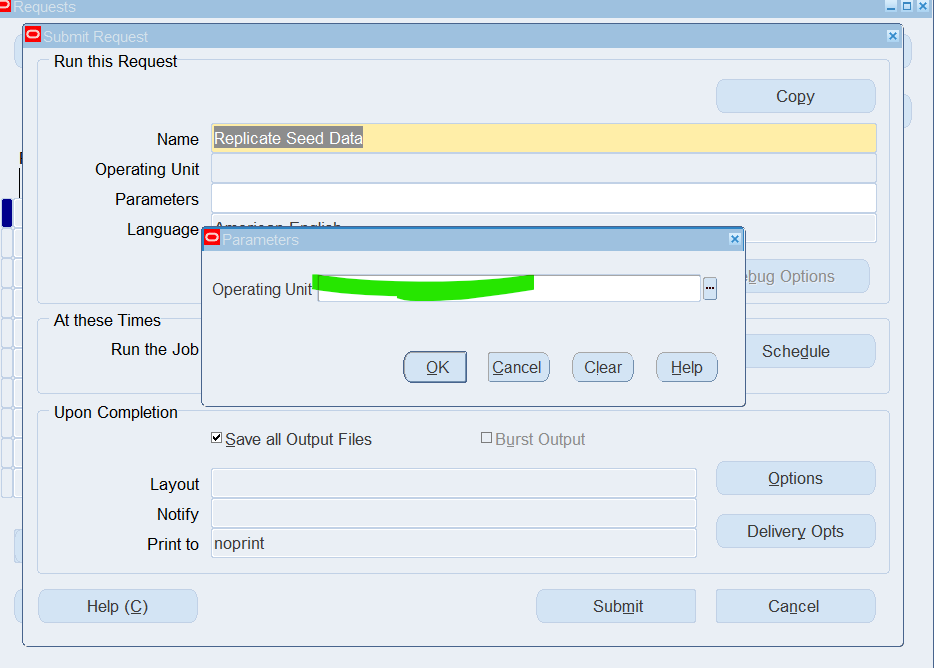
Select Single Request and Click Ok
Select the Replicate Seed Data From List of Values and select respective Operating Unit
Click Submit .
Responsibility: System Administrator
Replicate seed data concurrent request is used after defining operating unit so that all the seeded information will be reported to new operating unit. seeded information means default information in oracle applications.
Please reference the Replicate Seed Data step in the Oracle E-Business Suite Multiple Organizations Implementation Guide for more information.
The concept of the program is that whenever new organizations are created they should be should have seeded data from all relevant modules for normal integration among the modules. The seeded data is basic data needed to perform basic steps when setting up a new organization.
Running this program will not damage the system because it is providing a new organization with the basic information required to set up the organization.
Sample of seeded data
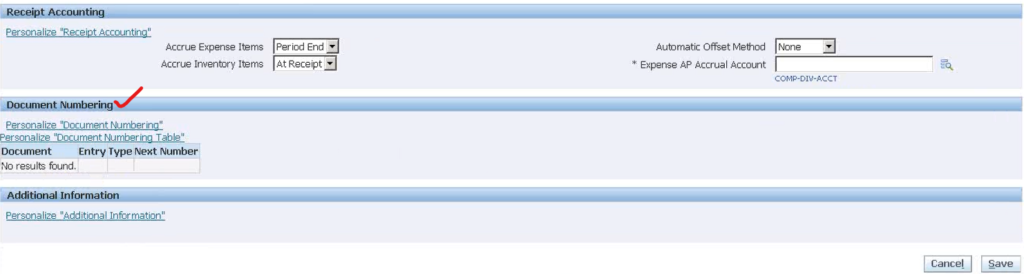
After running Replicate Seed Data following purchasing option “Document Numbering” available to configure for a operating unit.